提供給機器學習訓練的資料,必須先經過整合(若有多個資料集的情況)、資料格式轉換、處理缺失值及不一致的資料,確保資料是正確、乾淨一致的,避免 Garbage in, garbage out 問題,導致訓練出的模型結果預測不佳。
許多的資料集可能因為調查的對象拒絕回答、監控服務異常未抓取到數據等原因,所以包含缺失值,針對這些缺失值可以試著判別是否有特殊意義,可能在某特定情況下,這欄位有較大機會留空之類,若是此種情況,最好是標記成特殊值,或額外建立欄位表示值缺失,一起加入建模,但也有可能只是單純缺失值,是不重要、無意義的,這時需要透過移除或替代值來處理,在 Azure Machine Learning Studio 中,我們可以透過 Summarize Data 來查看每個欄位的資料是否還有缺失值,並使用 Clean Missing Data 來處理。
位置:Data Transformation / Manipulation / Clean Missing Data
清理方式有以下幾種:
(1) 以汽車資料集為例,新增"Summarize Data"統計資料,將資料集輸出接至 Summarize Data 的輸入並執行
位置:Statistical Functions / Summarize Data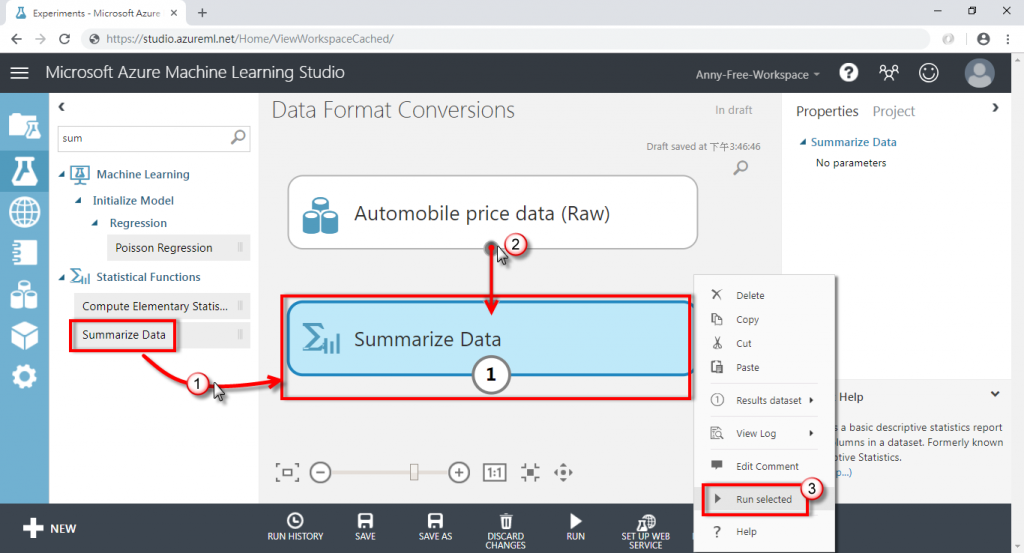
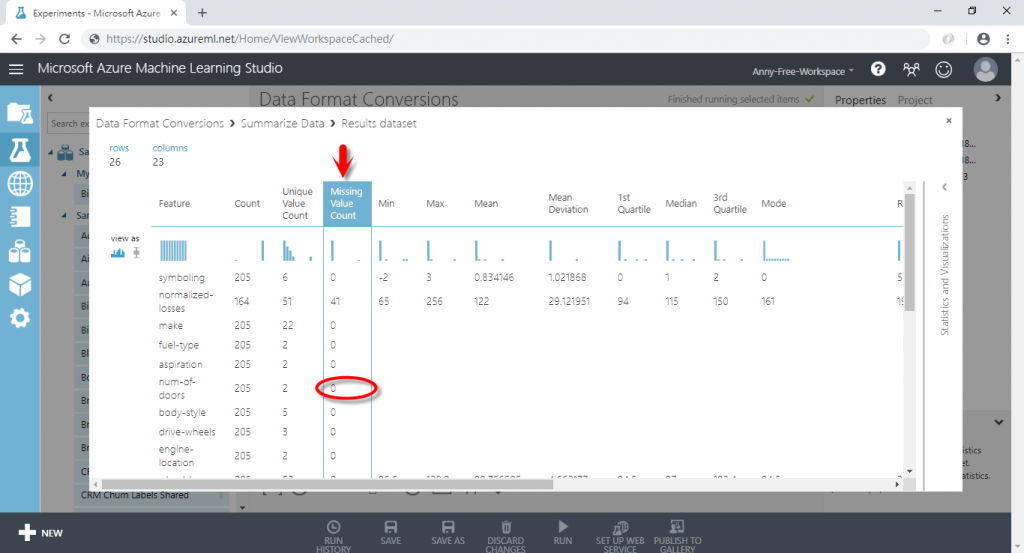
(2) 執行完成後,查看統計結果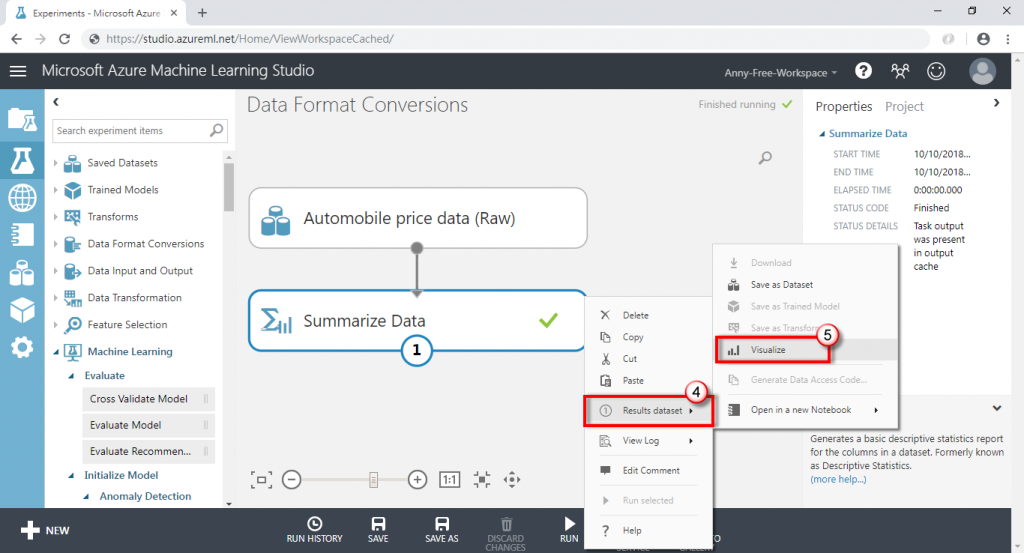
(3) 可以看到有些欄位的"Missing Value Count"有值,代表這些欄位有缺失值,其中 normalized-losses 欄位有 41 筆缺失值、num-of-doors 欄位有 2 筆缺失值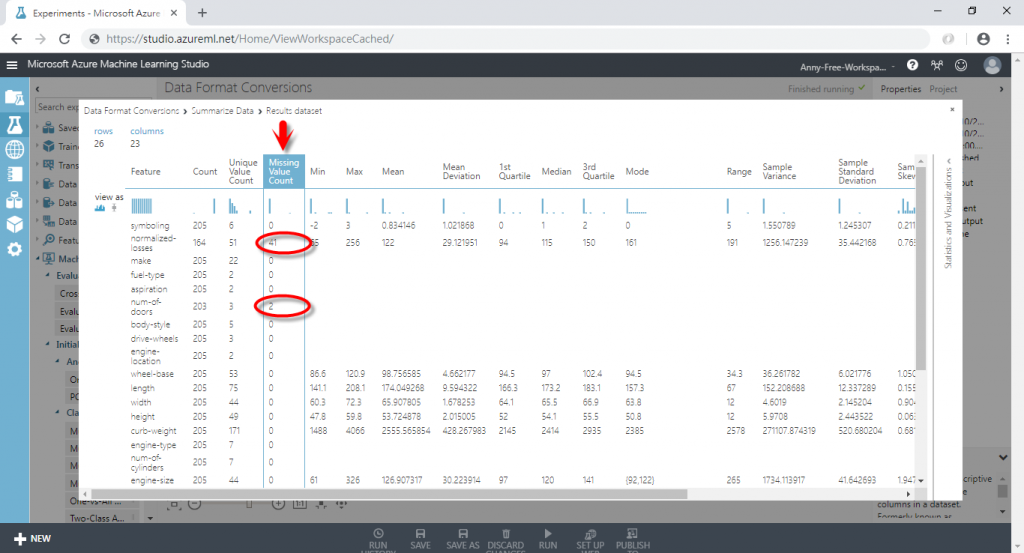
(4) 新增"Clean Missing Data"清理缺失值,將資料集的輸出接至 Clean Missing Data 的輸入,接著選擇有缺失值的欄位,若不選代表全部欄位一起處理
位置:Data Transformation / Manipulation / Clean Missing Data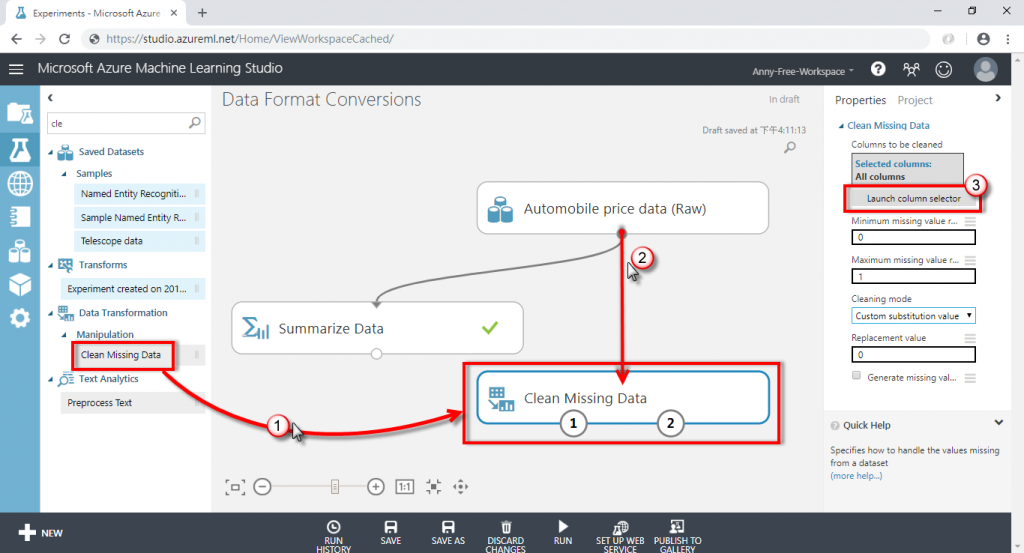
(5) 剛剛有看到"num-of-doors"幾門汽車的這個欄位有 2 筆缺失值,所以選擇此欄位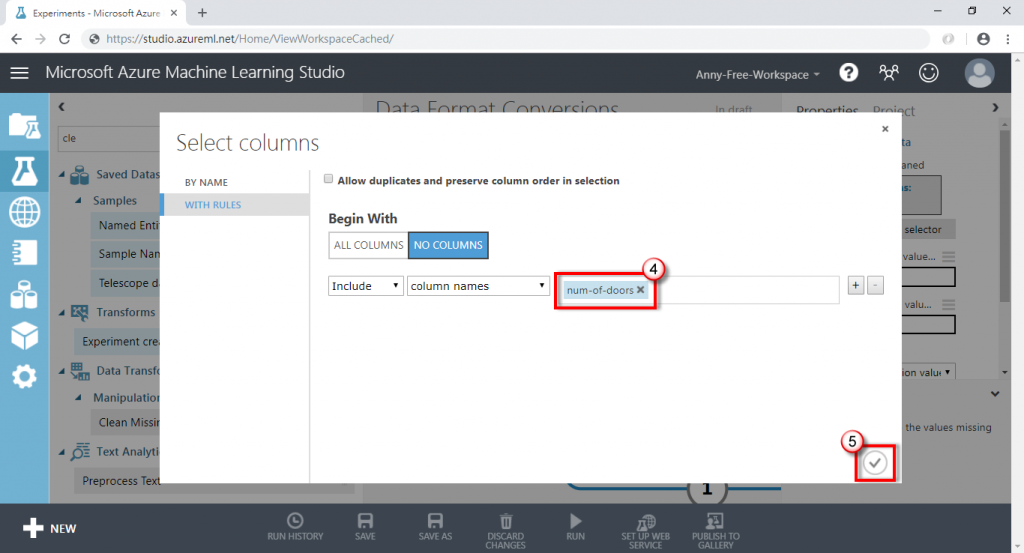
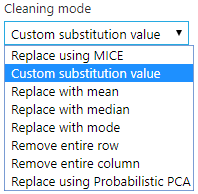
(6) 接著選擇缺失值的清理方法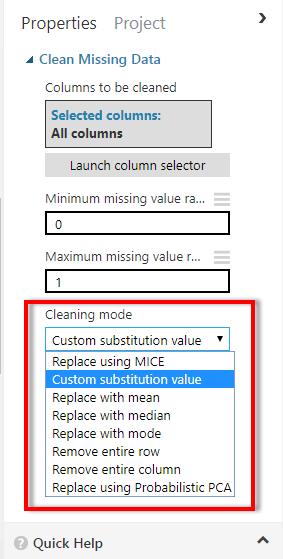
(7) 在選擇缺失值清理方式前可以先參考其他 203 筆無缺失值的資料值,以這個資料集為例,只有看到雙門跟四門的車子資料,這種情況,我就不會選擇用mean(平均數)、median(中位數)來取代缺失值,因為會導致資料變成特殊值,另外因為這個資料是字串,如果要使用平均數或中位數,必須先轉換資料型態,在這邊選擇用mode(眾數)處理,2 筆缺失值會用"four"取代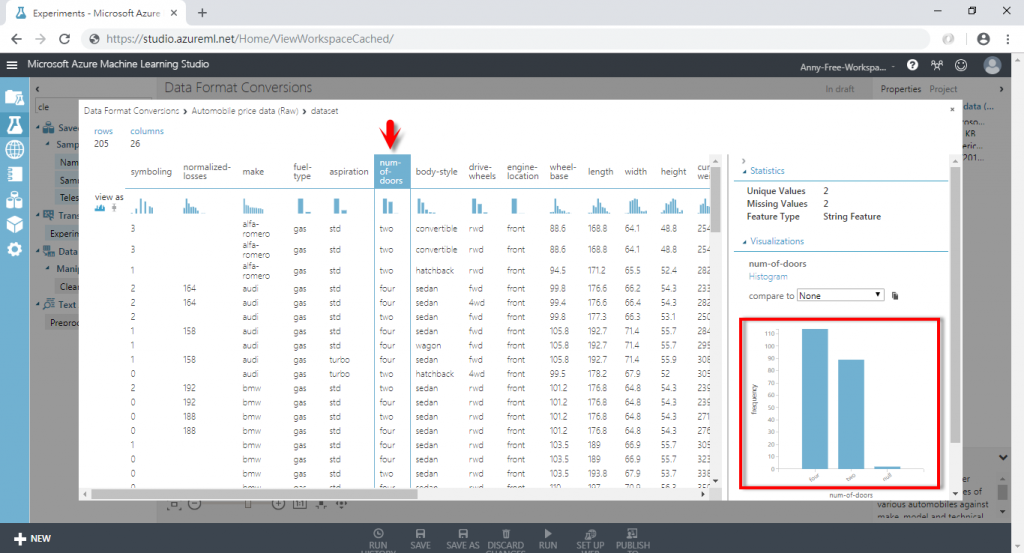
(8) 選擇缺失值清理方法"Replace with mode"以眾數取代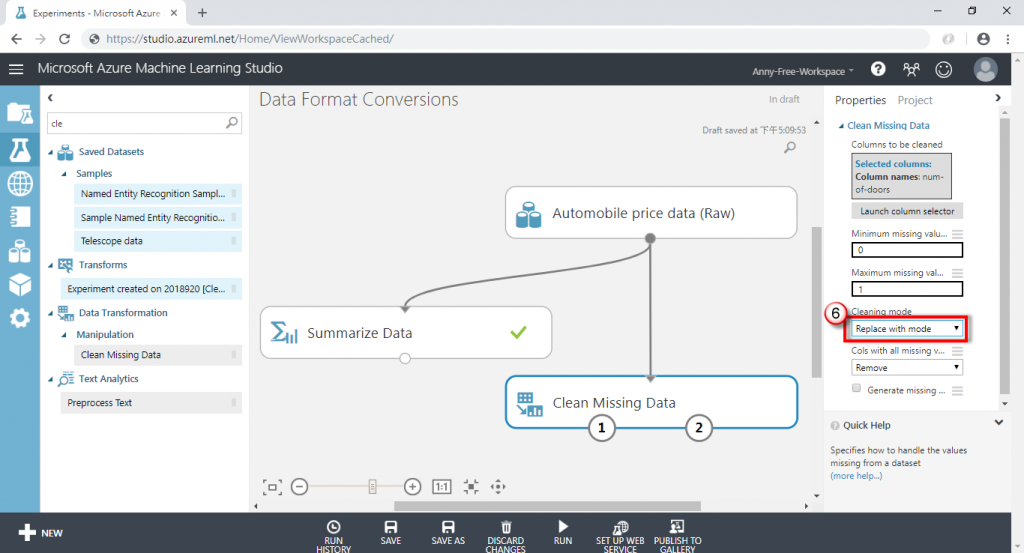
(9) 清理完後,可以再使用 Summarize Data 確認是否還有其他的缺失值要做處理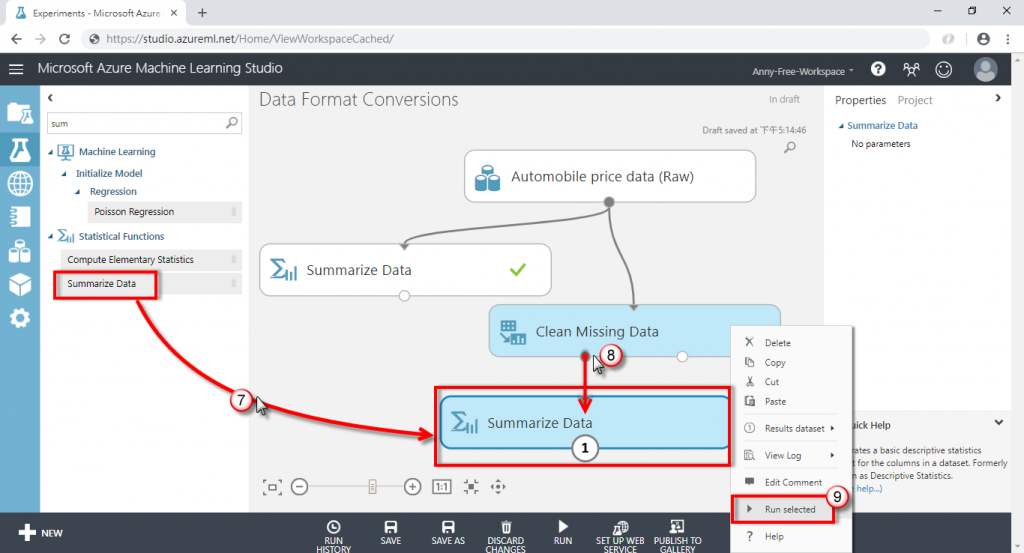
(10) 可以看到 num-of-doors 欄位缺失值資料數變為 0 筆,代表此欄位已無缺失值,接著可以再繼續處理其他的欄位,重複執行相同步驟一直到所有欄位的 Missing Value Count 皆為 0 時,代表處理完所有的缺失值資料了